We broke down some common misconceptions about open-source models for utilities.
With an uptick in literacy in Python and R, utilities are hearing the term “open source” more often. But, open source has already become ubiquitous in many industries. The 2019 Open Source Security and Risk Analysis Report found that 100% of the software operating at in the energy and cleantech has open-source code[1]. It stands to reason, then, that the UAI Analytics Architecture and Technology Community has open-source on its list of topics to explore. Specifically, when and how to leverage open source for utility-specific analytics and data science.
With “open-source” being used to describe developer tools, data, models, standards, frameworks, and platforms, it is important to define terms. The Miriam Webster definition of open source is software that has “source code freely available for possible modification and redistribution.” Freely accessible does not mean free of restrictions. For those who want to be “in the know”, Open Source Initiative has the most widely-accepted definition with ten different criteria for distribution, including accessibility and legal usability.
Like anything else, open source has its benefits and challenges. Here are two perspectives:
- “The combination of a transparent development community and access to public source code enables organizations to think differently about how they procure, implement, test, deploy, and maintain software. This has the potential to offer benefits, including reduced development costs, faster product development, higher code quality standards, and more.” European transmission system operator.
- “Open source technologies are dispersed, need customized support and often aren’t integrated. This lack of control over data and analytics heightens risks associated with maintenance, hidden costs, governance, and compliance.” Analytics vendor.
Open source in the utility context
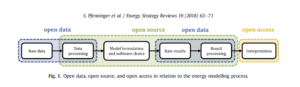
An excellent resource for understanding “open” is “Opening the black box of Energy modeling”[2], with examples of energy planning used by researchers and electric power system models used operationally by utilities. The article makes a distinction between open data (think DOE’s Open Energy Data Initiative) and open source (think two models for power simulation and analytics – pandapower for distribution systems and PowSybl[3] for regional transmission planning). See Figure 1.
The paper also outlines what questions to think about when thinking about going “open”:
- Who owns the intellectual property?
- What/how much should be published?
- Which license to choose? [Note: A myriad of open source licenses set boundaries on re-use; expertise in this area is a must.]
- Which modeling tools or language to choose?
- How to distribute code and data?
- How to provide support and build a community? [Note: Without governance and community committed to code development, the benefits of open source won’t be realized.]
The transparent nature of open source makes it easier to get to veracity; that question did not make the list above. Of course, how to provide security is an important question, along with the design of the architecture for necessary data ingestion, analysis, presentation and workflow that makes results usable in the organization (e.g., quickly providing control room operators with actions to take based on thousands of grid simulations).
In the next blog, we’ll look at open-source models and frameworks applicable to utility analytics.
[1]OSSRA, Synopsis Cybersecurity Research Center, based on an audit conducted by Blue It’s fair to assume that nascent industries like Cleantech use a lot of open-source. Note the many irradiance and wind prediction models on the software development platform Github.
[2] S. Pfenninger et al. / Energy Strategy Reviews 19 (2018) 63e71, 2018.
[3] OEDI and PowSyBl are both projects of LF Energy, an open-source umbrella organization within the Linux Foundation designed to establish open, interoperable frameworks for energy.