Digital twins are powerful representations of infrastructure. Increasingly used for representing electric utility grid networks, digital twins are what they say – a digital representation of the physical world. A digital twin should reflect the real world to a degree sufficient for the required analytics. Key challenges are their accuracy and that they are often not kept up to date over time. If done right, they provide a valuable pathway to planning, predictions and gaining insights into the physical assets they represent.
In addition to granular-level monitoring of utility assets, analytics can be built on top of digital twins for flexible and scalable grid planning projects. Using a digital twin, grid planners and analysts are empowered to develop use cases and what-if scenarios to make data-backed business decisions and regulatory filings. The process can result in significant operational expenditure (OPEX) and capital expenditure (CAPEX) savings, lower costs for utilities and their customers.
For digital twins to be useful for analytics, they must bring together data of different types and from different systems into a single, trustworthy shape that can be easily accessed. Broadly speaking, these data include time series, geographic, connectivity and asset attribute data about the grid – all of which must be cross-referenced and synchronized. The image below shows what visualizing a digital twin of the electric grid might look like. But the utility of digital twins goes far beyond merely enabling easy visualization of the grid. It also includes programmatic access to electric grid data via standardized APIs, backed by a schema or data model.
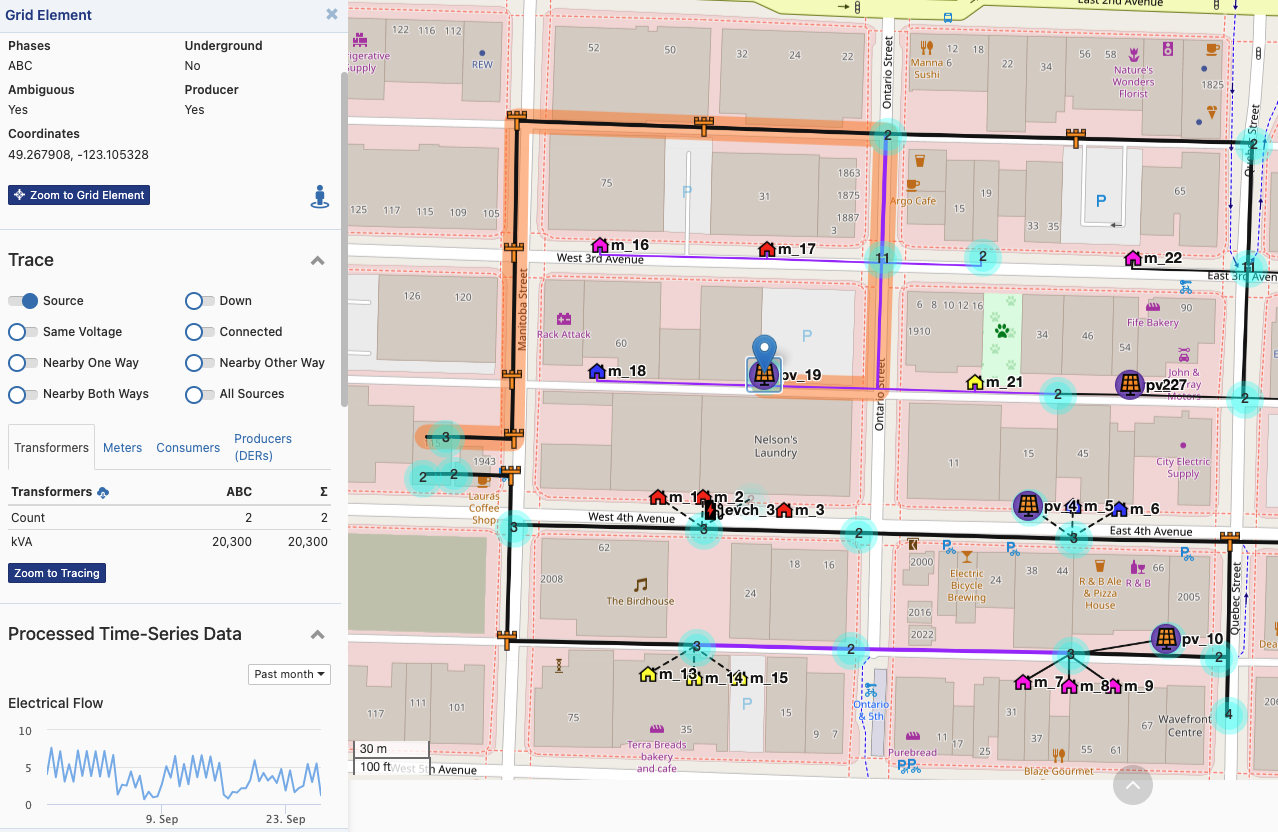
Awesense. (2022, May). True Grid Intelligence.
Preparing electric grid data for a digital twin
Two key steps in building a trustworthy, easy to use digital twin are data cleansing and data synchronization. Data cleansing is the process of validating, estimating, and correcting errors in the data. Data synchronizing is the process of ensuring all the parts of the data properly cross-reference each other and are represented with respect to time and space. Data cleansing and synchronization are difficult to achieve for three reasons:
- Poor data quality due to errors or outdated standards.
- Data is scattered across many source systems and stored in unique and/or proprietary formats.
- The sheer volume of data points, which can be in the tens of millions of grid assets and billions of associated time series measurements.
Up until the introduction of validation, estimation, and error correction (VEE) data engines, data cleansing and synchronization were major undertakings. Teams of data analysts, scientists and engineers could spend months to even years performing manual data investigation and field trip (“truck roll”) assessments in order to cleanse data. This can greatly extend project timespan, with 80% of the work being low-value work such as repetitive data correction and validation tasks. VEE engines alternatively offer rapid and effective data validation, estimation, and correction processes that allow data teams to focus on the analytics portions of the projects.
Why is it so difficult to make grid data work in a digital twin?
Grid analytics often require data from multiple source systems. Directly accessing them all is challenging. This is a problem digital twins solve. Time series, geographic, connectivity and asset attribute data comes from different sources and can be stored in multiple different formats. Examples of such data sources include geographic information systems (GIS), customer information systems (CIS), AMI, MV90 or manual metering systems, SCADA, EVSE, SolarPV, Storage, IoT, and more. Formats include, but are not limited to, geo-databases, Multispeak, CIM, and IEC 61850.
For example, a utility that’s building analytics to plan outages for asset upgrades uses time series data from assets, outage management system data, and GIS data. Depending on the volume of data and number of errors – of which there are typically many found in GIS data – validation, estimation, correction, and synchronization thereafter could require a team of many people and many months if done using manual methods.
In another example, a utility seeking to analyze transformer capacity for EV charging will need to leverage both time series and geographic data from EVSE, AMI, mid-feeder assets, and GIS sources. Normalizing time series data is a challenge in this use case. It is very common for assets’ time series data to vary in granularity of timestamps or time shifts. Teams trying to do this from scratch will spend a considerable amount of time just bringing all the data together and synchronizing it before they can even start implementing the actual analytics.
There are almost always errors in the various systems where data comes from, so in order for it to enable trustworthy analytics, these errors must be identified and resolved. VEE engines are a key component of the process of building a digital twin because they help automate parts of the data cleansing process, dramatically accelerating the outcome. Examples of errors commonly found and corrected for by VEE engines include:
- Attributes & coordinates validation and transformation
- Connectivity validation, estimation and correction
- Meter association validation
- Switch state validation and correction
- Time series data validation and synchronization
- Missing time series data estimation
In order for VEE engines to be able to provide automation for these processes, it is important that the data is shaped according to a standard or schema, typically referred to as a data model. This allows the VEE engines to be re-used and re-run without additional development effort.
Data correction and synchronization’s heavy lifting
Robust data analysis depends on the quality of the data being analyzed. A digital twin and related analytics must be built on reliable data. VEE engines run algorithms based on analytical and mathematical principles to identify and correct anomalous data. The process is iterative and will run over corrected datasets so as to identify errors uncovered or previously missed. More advanced VEE engines use artificial intelligence (AI) and machine learning (ML) solutions that train algorithms to look for specific errors and patterns in datasets.
The output of the VEE engine is a cleansed and structured data set, in other words a data-model backed digital twin, ready for practically endless analytics, use case development, and predictive modeling. A digital twin can be automatically updated with data streams so that it reflects the grid’s state in near real-time. The number of use cases that can be developed on top of a digital twin is vast, the only limitation being the data that comes from grid-connected sources. Use cases include power factor analysis, asset management use cases of cables, lines, and substations, DER planning, and many more. Digital twins serve as data warehouses for these developments. They also allow for AI and ML-based analytics tools to run advanced analyses.
Streamlined data processes maximize team resources
Many teams at utilities and their contractor partners are well aware of the challenges and resource commitment necessary to prepare data for analytics. The data available for analytics projects are also only getting larger with more data types arising with higher frequency and velocity. Allowing your people to focus their efforts on the most important task at hand, and the most enjoyable, the actual analytics and use case, can enable higher overall team satisfaction.
Tools like VEE engines offer grid planning teams a faster route to reliable electric grid data, are human-interactive, and offer flexible access across teams. For example, before correcting data, a VEE engine identifies issues and presents them to a human operator along with suggested corrections. The operator can then approve these corrections, which can subsequently be automated for future iterations. This approach ensures continuous improvement and refinement of grid data, providing a robust foundation for reliable and efficient grid management. Data used in a digital twin can be retrieved via APIs, making it accessible across multiple teams to facilitate reuse and encourage collaboration. The above benefits not only project progress, but also skill development within the teams executing the project.
VEE engines, backed by a data model and powered by non-generative AI/ML and other powerful algorithms, enable grid planning teams to manage data cleansing and synchronization on their own with reasonable timelines and budget. Managing costs and gaining data insight are critical in the current utility climate, where major changes are underway. As utilities pursue their goals related to renewable energy, DERs, and smart grid technology deployment, they can leverage the value of their grid data at a reasonable cost. VEE engines, and their acceleration of digital twin and analytics creation, offer a way for teams to achieve both, as well as maintain robust operation in their grid planning teams.
About the Author
Elena Popovici is the CTO of Awesense. She holds a Ph.D. in computer science and has managed science driven software projects for over 15 years across various domains. At Awesense, she oversees the software development and data science for decision support as part of their full technology stack.

is a member of